ClickHouse Alternatives: Top Competitors That Replicate Its Power for Big Data Needs
ClickHouse Alternatives: Top Competitors That Replicate Its Power for Big Data Needs
When businesses demand fast, scalable, and columnar data processing, ClickHouse often emerges as the golden standard—especially for real-time analytics and high-performance OLAP workloads. But no platform dominates every use case, and organizations constantly weigh alternatives like Apache Druid, Amazon Redshift, Snowflake, Apache Pinot, and Vertica. This deep dive compares the leading ClickHouse competitors across key dimensions—speed, scalability, SQL compatibility, cost, and enterprise readiness—to help data teams choose the right tool for mission-critical reporting and analytics.
ClickHouse’s rise in the analytics landscape has spurred fierce competition.
While it excels at handling petabytes of time-series and transactional data with lightning-fast ingestion and complex aggregations, its competitors offer unique trade-offs—some emphasizing cloud-native simplicity, others focusing on hybrid architectures or enterprise-grade features. Understanding these nuances is essential for organizations aiming to build robust, future-proof data pipelines.
This article investigates the top ClickHouse alternatives—not just as replacements, but as sophisticated ecosystems each tailored to distinct real-world demands. From SQL-driven flexibility to native real-time streaming and AI-augmented query optimization, the comparative analysis reveals which platforms truly deliver on scalability, usability, and total cost of ownership.
Apache Druid: Real-Time Analytics with a Columnar Edge
Apache Druid stands out as one of ClickHouse’s closest competitors, especially for real-time data ingestion and rapid ad-hoc querying.
Designed for sub-second response times, Druid’s in-memory columnar architecture enables efficient handling of high-cardinality data streams—making it a strong fit for IoT, user activity, and financial tick data. Unlike ClickHouse’s SCAN-based execution, Druid employs a distributed metastore and fan-out-download model that excels under continuous write loads.
While both systems support SQL, Druid’s query engine prioritizes exact match and time-series aggregations with low-latency execution. It features built-in compression, time-based partitioning, and native support for real-time dashboards.
However, Druid’s operational complexity—particularly around cluster tuning and recovery—can be steeper than ClickHouse’s more streamlined deployment. Pricing aligns with cloud offerings, often requiring provisioned storage and compute, though its flexible resource model helps control costs for variable workloads.
Druid’s niche shines in enterprise environments where event-time accuracy and governed data retention are critical. Yet, for teams needing seamless integration with machine learning pipelines or visual analytics tools, Druid’s ecosystem remains less mature compared to some peers.
Amazon Redshift: Classic Warehouse Meets Modern Scalability
Amazon Redshift remains a dominant force in the SQL analytics space, especially for enterprises invested in AWS infrastructure.
Unlike ClickHouse’s open-source, columnar core, Redshift uses a columnar storage format optimized for enterprise-grade workloads, combining robust security, seamless cloud integration, and managed infrastructure. Its node-style architecture scales horizontally to petabyte-sized datasets, while RA3 nodes enable concurrent streaming and workload management—reducing query contention.
While Redshift’s performance on bulk ETL and complex joins benefits from CDO-style indexing and distribution keys, its SQL interface, though familiar, lacks some advanced features like ClickHouse’s native support for JSON arrays or flexible time-series aggregation without preprocessing. Cost efficiency improves with reserved instances and data compression, but operational overhead grows with cluster customization.
Redshift excels where multi-tenancy, compliance, and hybrid cloud integration are priorities, though nascent serverless variants vie for modern deployment flexibility.
For legacy data platforms transitioning to cloud, Redshift offers stability and vendor support—but innovators seeking cutting-edge analytics engine features may find newer alternatives more compelling.
Snowflake: Cloud-Native Analytics with Unmatched Flexibility
Snowflake has redefined cloud data warehousing with its multi-cloud, multi-cluster, and serverless architecture, offering a compelling alternative to closed systems like ClickHouse and Redshift. Its architecture separates storage and compute, enabling elastic scale on demand—particularly valuable for variable-scale analytics teams. Snowflake’s SQL interface, built for ease of use and extensibility, supports advanced analytics, user-defined functions, and JSON/ARRAY handling with minimal friction.
What sets Snowflake apart is its unique architecture: isolate logical partitions, accelerated compression, and seamless data sharing across neighborhoods simplify collaboration and security.
Built for petabyte-scale workloads, it matches ClickHouse in ingestion speed but excels in ease of integration with BI tools, machine learning services, and third-party applications. Enterprises gain pay-per-query pricing and built-in data governance, reducing operational burden. Yet, true instance-level optimization lags behind Druid’s fan-out model, and query cost efficiency can suffer with high concurrency.
For organizations embracing a shadow IT or multi-cloud strategy, Snowflake’s broad ecosystem and self-service agility make it a top contender—even if raw columnar performance varies across use cases.
Apache Pinot: Real-Time Streaming Close to the Source
Apache Pinot, originally developed at LinkedIn, targets low-latency, real-time analytics on stream ingestion—complementing ClickHouse’s strengths while focusing on enterprise-grade operational reliability.
Unlike ClickHouse’s batch/stream hybrid ingestion, Pinot emphasizes persistent, low-latency query performance over continuously updated datasets, making it ideal for serving real-time dashboards with millisecond responsiveness.
Pinot’s architecture supports store-on-write and incremental refreshes, enabling precise control over data freshness. While SQL support is robust and schema design leans toward time-series patterns, it lacks some of ClickHouse’s flexibility in complex aggregation chains. Pinot integrates tightly with Kafka and streaming platforms, reducing pipeline complexity for event-driven architectures.
Yet, its deployment complexity and steep learning curve often require dedicated DevOps and data engineering expertise.
In environments where real-time editing of live data streams—such as personalized recommendations or network monitoring—is mission-critical, Pinot delivers precision and consistency unmatched by many peers, though total cost of ownership remains higher than simpler alternatives.
Vertica: The Traditional Warehouse with Enterprise Polish
Vertica, a legacy SQL OLAP powerhouse, delivers high performance through a unique in-memory, columnar engine optimized for predictable, batch-heavy workloads. Its compression algorithms and query optimization target dense, structured datasets—excelling in data warehousing scenarios requiring deep analytical complexity and mission-critical reliability. While not day-one open source like ClickHouse, Vertica’s enterprise features, such as data virtualization and governance, appeal to regulated industries.
Though Vertica supports SQL with rich window functions and subquery flexibility, its architecture favors static data loads over high-velocity ingestion, limiting real-time use cases.
It integrates tightly with existing enterprise stacks but lacks the agility and open-source ecosystem observed in modern competitors. For organizations with long-term data warehouse commitments and complex SQL workloads, Vertica remains a solid, if older, alternative—especially where backward compatibility and governance exceed raw speed.
Performance Benchmarking: Who Holds the Edge?
Raw speed benchmarks highlight distinct performance profiles: - Druid leads in ultra-low-latency response for time-series and event-time queries at scale. - Pinot delivers deterministic sub-second latency for streaming workloads requiring consistency.
- ClickHouse dominates in aggregate complexity and hybrid batch-streaming ingestion with its SCAN paradigm. - Redshift excels in bulk ETL and complex join performance within the AWS ecosystem. - Snowflake offers elastic compute scaling but trades raw query speed for flexibility.
- Vertica maintains strong performance in structured batch workloads with heavy analytic computation but falters in rapid ingestion. No single platform outperforms ClickHouse across all dimensions—each shines in specific contexts tied to data velocity, infrastructure, and operational model.
Cost and Ecosystem Realities
Open-source roots keep ClickHouse cost-efficient, particularly with self-managed or cloud-native deployments. Druid’s TikoDB storage adds infrastructure complexity, while Redshift and Snowflake charge based on compute consumption—often with reserved instances offering savings at scale.
Pinot’s operational overhead and specialized hardware needs increase total cost, and Vertica’s licensing model remains enterprise-heavy.
Ecosystem maturity varies: Snowflake offers the broadest BI and ML integrations; Druid tightly couples with Apache tools; Pinot integrates deeply with Kafka; ClickHouse benefits from a vibrant community but lacks some enterprise tooling. For teams prioritizing open standards and vendor neutrality, ClickHouse’s cost-speed balance resonates—unless ecosystem lock-in or feature depth mandates a premium platform.
The Path Forward: Choosing Your Analytics Foundation
Selecting a ClickHouse competitor demands a clear-eyed assessment of technical requirements, team expertise, and long-term strategy.
For real-time, event-time rich analysis, Druid or Pinot deliver precision. In cloud-first environments, Snowflake’s elasticity and integration win hands. Legacy systems may still depend on Vertica, while Redshift suits AWS-native data center workflows.
Ultimately, no breeding ground exceeds ClickHouse’s core formula—columnar speed, flexible SQL, and high-volume ingestion—but the right alternative emerges when specific use cases demand tailored trade-offs in latency, scalability, and cost. As analytics evolve toward hybrid, real-time, and distributed architectures, organizations must balance innovation with operational pragmatism to build resilient, future-ready data platforms.


Related Post

Behind the Screen: The Private Life of Steve Tracy’s Wife
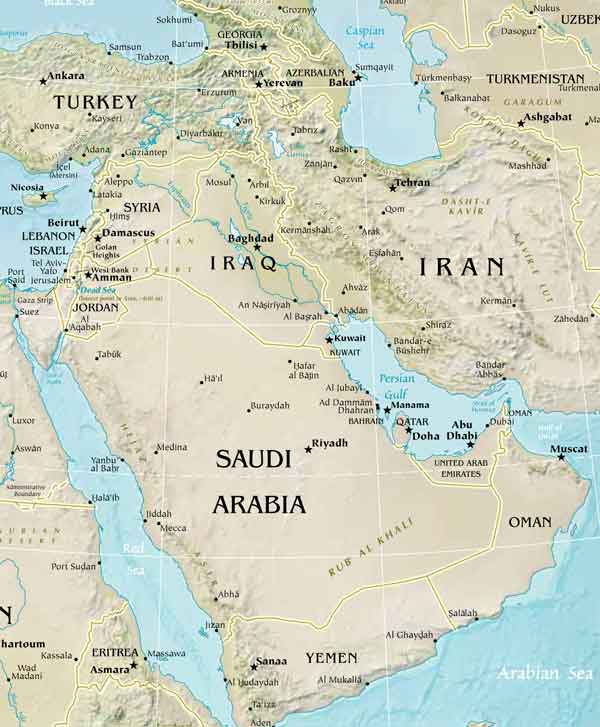
The Physical Map of Southwest Asia: A Tapestry of Mountains, Deserts, and Strategic Crossroads

Carly Corinthos at 34: The Rising Star Defining Modern Countrycha with Poise and Power

Mastering the Boycott List: How Consumer Activism Shapes Global Markets



